The White House Office of Science and Technology Policy has announced plans to co-host four public workshops to spur public dialogue on artificial intelligence and machine learning, and to learn more about the benefits and risks of artificial intelligence, according to Ed Felten, a Deputy U.S. Chief Technology Officer.
These four workshops will be co-hosted by academic and non-profit organizations; two will also be co-hosted by the National Economic Council, with a public report later this year. They will be livestreamed:
The Federal Government also is “working to leverage AI for public good and toward a more effective government.” A new National Science and Technology Council (NSTC) Subcommittee on Machine Learning and Artificial Intelligence will monitor state-of-the-art advances and technology milestones in artificial intelligence and machine learning within the Federal Government, in the private sector, and internationally; and help coordinate Federal activity in this space.
The NSTC group also hopes to increase the use of AI and machine learning to improve the delivery of government services, especially in areas related to urban systems and smart cities, mental and physical health, social welfare, criminal justice, and the environment.
A hybrid hydrostatic transmission and human-safe haptic telepresence robot (credit: Disney Research)
A human-safe lifelike telepresence robot with the delicacy and precision needed to pick up an egg without breaking it or thread a sewing needle has been developed by researchers at Disney Research, the Catholic University of America, and Carnegie Mellon University.
The secret: a hydrostatic transmission that precisely drives robot arms, offering extreme precision with almost no friction or play.
The hybrid transmission design also makes it possible to halve the number of bulky hydraulic lines that a fully hydraulic system would require and allows for making its robotic limbs lighter and smaller, said John P. Whitney, an assistant professor of mechanical and industrial engineering at Northeastern University, who led the development of the transmission while an associate research scientist at Disney Research.
Whitney said a robot joint normally would have two hydraulic cylinders, balanced against each other. But in this latest design, the researchers paired each water-filled cylinder with an air-filled cylinder instead. The pneumatic cylinder serves as a constant force air-spring, providing the necessary preload force and allowing the joint to move in both directions with only half the number of bulky hydraulic lines.
Lifelike interaction with people
The researchers used the new transmission to build a simple humanoid robot with two arms, with stereo cameras mounted in the head, streaming their video signal to an operator wearing a head-mounted display. The arms are coupled to an identical control figure to enable the robot to be used for human-robot interaction research.
“This technology enabled us to build robot arms that are light, fast, and dexterous,” Whitney said. “They have an incredible lifelike nature, offering a combination of small mass, high speed, and precise motion not seen before.”
Robots using this technology are ideally suited for naturally compliant and lifelike interaction with people. When tele-operated, the low friction and lack of play allow the transmission to faithfully transmit contact forces to the operator, providing a high-fidelity remote sense of touch.
Whitney and colleagues will report on the new transmission and the upper body humanoid robot they built with it at the IEEE Conference on Robotics and Automation, ICRA 2016, May 17 in Stockholm, Sweden.
Disney Research | A Hybrid Hydrostatic Transmission and Human Safe Haptic Telepresence Robot
Abstract of A Hybrid Hydrostatic Transmission and Human-Safe Haptic Telepresence Robot
We present a new type of hydrostatic transmission that uses a hybrid air-water configuration, analogous to N+1 cable-tendon transmissions, using N hydraulic lines and 1 pneumatic line for a system with N degrees of freedom (DOFs). The common air-filled line preloads all DOFs in the system, allowing bidirectional operation of every joint. This configuration achieves the high stiffness of a water-filled transmission with half the number of bulky hydraulic lines. We implemented this transmission using pairs of rolling-diaphragm cylinders to form rotary hydraulic actuators, with a new design achieving a 600-percent increase in specific work density per cycle. These actuators were used to build a humanoid robot with two 4-DOF arms, connected via the hydrostatic transmission to an identical master. Stereo cameras mounted on a 2-DOF servo-controlled neck stream live video to the operator’s head-mounted display, which in turn sends the real-time attitude of the operator’s head to the neck servos in the robot. The operator is visually immersed in the robot’s physical workspace, and through the bilateral coupling of the low-impedance hydrostatic transmission, directly feels interaction forces between the robot and external environment. We qualitatively assessed the performance of this system for remote object manipulation and use as a platform to safely study physical human-robot interaction.
Google has just released two powerful natural language understanding tools for free, open-source use by anyone. These tools allow machines to read and understand English text (such as text you type into a browser to do a Google search).
SyntaxNet is a “syntactic parser” — it allows machines to parse, or break down, sentences into their component parts of speech and identify the underlying meaning). And the Parsey McParseface program implements SyntaxNet in English (it learned from an annotated collection of old newswire stories called The Penn Treebank Project).
On a standard benchmark consisting of randomly drawn English newswire sentences (“Penn Treebank”), Parsey McParseface recovers individual dependencies between words with over 94% accuracy, Google says. ”Linguists trained for this task agree in 96–97% of the cases. This suggests that we are approaching human performance—but only on well-formed text.
“Because Parsey McParseface is the most accurate such model in the world, we hope that it will be useful to developers and researchers interested in automatic extraction of information, translation, and other core applications of NLU,” says Google.
This five-fingered robot hand developed by University of Washington computer science and engineering researchers can learn how to perform dexterous manipulation — like spinning a tube full of coffee beans — on its own, rather than having humans program its actions. (credit: University of Washington)
A University of Washington team of computer scientists and engineers has built what they say is one of the most highly capable five-fingered robot hands in the world. It can perform dexterous manipulation and learn from its own experience without needing humans to direct it.
“Hand manipulation is one of the hardest problems that roboticists have to solve,” said lead author Vikash Kumar, a UW doctoral student in computer science and engineering. “A lot of robots today have pretty capable arms but the hand is as simple as a suction cup or maybe a claw or a gripper.”
The UW research team has developed an accurate simulation model that enables a computer to analyze movements in real time. In their latest demonstration, they apply the model to the robot hardware and to real-world tasks like rotating an elongated object.
Autonomous machine learning
With each attempt, the robot hand gets progressively more adept at spinning the tube, thanks to machine learning algorithms that help it model both the basic physics involved and plan which actions it should take to achieve the desired result. (This demonstration begins at 1:47 in the video below.)
University of Washington | ADROIT Manipulation Platform
This autonomous-learning approach developed by the UW Movement Control Laboratory contrasts with robotics demonstrations that require people to program each individual movement of the robot’s hand to complete a single task.
Building a dexterous, five-fingered robot hand poses challenges, both in design and control. The first involved building a mechanical hand with enough speed, strength, responsiveness, and flexibility to mimic basic behaviors of a human hand.
The UW’s dexterous robot hand — which the team built at a cost of roughly $300,000 — uses a Shadow Hand skeleton actuated with a custom pneumatic system and can move faster than a human hand and with 24 degrees of freedom (types of movement). It is too expensive for routine commercial or industrial use, but it allows the researchers to push core technologies and test innovative control strategies.
The team first developed algorithms that allowed a computer to model highly complex five-fingered behaviors and plan movements to achieve different outcomes — like typing on a keyboard or dropping and catching a stick — in simulation. Then they transferred the models to work on the actual five-fingered hand hardware. As the robot hand performs different tasks, the system collects data from various sensors and motion capture cameras and employs machine learning algorithms to continually refine and develop more realistic models.
So far, the team has demonstrated local learning with the hardware system, which means the hand can continue to improve at a discrete task that involves manipulating the same object in roughly the same way. Next steps include beginning to demonstrate global learning, which means the hand could figure out how to manipulate an unfamiliar object or a new scenario it hasn’t encountered before.
The research was funded by the National Science Foundation and the National Institutes of Health.
Abstract of Optimal Control with Learned Local Models: Application to Dexterous Manipulation
We describe a method for learning dexterous manipulation skills with a pneumatically-actuated tendon-driven 24-DoF hand. The method combines iteratively refitted timevarying linear models with trajectory optimization, and can be seen as an instance of model-based reinforcement learning or as adaptive optimal control. Its appeal lies in the ability to handle challenging problems with surprisingly little data. We show that we can achieve sample-efficient learning of tasks that involve intermittent contact dynamics and under-actuation. Furthermore, we can control the hand directly at the level of the pneumatic valves, without the use of a prior model that describes the relationship between valve commands and joint torques. We compare results from learning in simulation and on the physical system. Even though the learned policies are local, they are able to control the system in the face of substantial variability in initial state.
Feedback from experiments: augmented dataset with four new alloys (credit: Los Alamos National Laboratory)
Scientists at Los Alamos National Laboratory and the State Key Laboratory for Mechanical Behavior of Materials in China have used a combination of machine learning, supercomputers, and experiments to speed up discovery of new materials with desired properties.
The idea is to replace traditional trial-and-error materials research, which is guided only by intuition (and errors). With increasing chemical complexity, the possible combinations have become too large for those trial-and-error approaches to be practical.
The scientists focused their initial research on improving nickel-titanium (nitinol) shape-memory alloys (materials that can recover their original shape at a specific temperature after being bent). But the strategy can be used for any materials class (polymers, ceramics, or nanomaterials) or target properties (e.g., dielectric response, piezoelectric coefficients, and band gaps).
Cutting time and cost of creating new materials
“What we’ve done is show that, starting with a relatively small data set of well-controlled experiments, it is possible to iteratively guide subsequent experiments toward finding the material with the desired target,” said principal investigator Turab Lookman, a physicist and materials scientist in the Physics of Condensed Matter and Complex Systems group at Los Alamos. “The goal is to cut in half the time and cost of bringing materials to market,” he said.
The impetus for the research was a 2013 announcement by the Obama Administration and academic and industry partners of the Materials Genome Initiative, a public-private endeavor that aims to cut in half the time it takes to develop novel materials that can fuel advanced manufacturing and bolster the American economy. This new study is one of the first to demonstrate how an informatics framework can do that.*
Adaptive design framework (credit: Los Alamos National Laboratory)
Although the new research focused on the chemical exploration space, it can be readily adapted to optimize processing conditions when there are many “tuning knobs” controlling a figure of merit, as in advanced manufacturing applications, or to optimize multiple properties, such as (in the case of the nickel-titanium-based alloy) low dissipation and a transition temperature several degrees above room temperature.
The research was published in an open-access paper in Nature Communications. The Laboratory Directed Research and Development (LDRD) program at Los Alamos funded the work and the lab provided institutional computing resources.
* Much of the effort in the field has centered on generating and screening databases typically formed by running thousands of quantum mechanical calculations. However, the interplay of structural, chemical and microstructural degrees of freedom introduces enormous complexity, especially if defects, solid solutions, and multi-component compounds are involved, which the current state-of-the-art tools are not yet designed to handle. Moreover, few studies include any feedback to experiments or incorporate uncertainties. This becomes important when experiments or calculations are costly and time-consuming.
Abstract of Accelerated search for materials with targeted properties by adaptive design
Finding new materials with targeted properties has traditionally been guided by intuition, and trial and error. With increasing chemical complexity, the combinatorial possibilities are too large for an Edisonian approach to be practical. Here we show how an adaptive design strategy, tightly coupled with experiments, can accelerate the discovery process by sequentially identifying the next experiments or calculations, to effectively navigate the complex search space. Our strategy uses inference and global optimization to balance the trade-off between exploitation and exploration of the search space. We demonstrate this by finding very low thermal hysteresis (ΔT) NiTi-based shape memory alloys, with Ti50.0Ni46.7Cu0.8Fe2.3Pd0.2 possessing the smallest ΔT (1.84 K). We synthesize and characterize 36 predicted compositions (9 feedback loops) from a potential space of ~800,000 compositions. Of these, 14 had smaller ΔT than any of the 22 in the original data set.
A visualization of the model taken at one time point while running. Each sphere represents a computational unit, with lines representing the connection between units. The colors represent the output of each unit. The left and right of the image are the inputs to the model and the center is the output, which is used to guide the virtual bee down a simulated corridor. (credit: The University of Sheffield)
A computer model of how bees use vision to avoid hitting walls could be a breakthrough in the development of autonomous drones.
Bees control their flight using the speed of motion (optic flow) of the visual world around them. A study by Scientists at the University of Sheffield Department of Computer Science suggests how motion-direction detecting circuits could be wired together to also detect motion-speed, which is crucial for controlling bees’ flight.
“Honeybees are excellent navigators and explorers, using vision extensively in these tasks, despite having a brain of only one million neurons,” said Alex Cope, PhD., lead researcher on the paper. “Understanding how bees avoid walls, and what information they can use to navigate, moves us closer to the development of efficient algorithms for navigation and routing, which would greatly enhance the performance of autonomous flying robotics,” he added.
“Experimental evidence shows that they use an estimate of the speed that patterns move across their compound eyes (angular velocity) to control their behavior and avoid obstacles; however, the brain circuitry used to extract this information is not understood, ” the researchers note. “We have created a model that uses a small number of assumptions to demonstrate a plausible set of circuitry. Since bees only extract an estimate of angular velocity, they show differences from the expected behavior for perfect angular velocity detection, and our model reproduces these differences.”
Their open-access paper is published in PLOS Computational Biology.
Abstract of A Model for an Angular Velocity-Tuned Motion Detector Accounting for Deviations in the Corridor-Centering Response of the Bee
We present a novel neurally based model for estimating angular velocity (AV) in the bee brain, capable of quantitatively reproducing experimental observations of visual odometry and corridor-centering in free-flying honeybees, including previously unaccounted for manipulations of behaviour. The model is fitted using electrophysiological data, and tested using behavioural data. Based on our model we suggest that the AV response can be considered as an evolutionary extension to the optomotor response. The detector is tested behaviourally in silico with the corridor-centering paradigm, where bees navigate down a corridor with gratings (square wave or sinusoidal) on the walls. When combined with an existing flight control algorithm the detector reproduces the invariance of the average flight path to the spatial frequency and contrast of the gratings, including deviations from perfect centering behaviour as found in the real bee’s behaviour. In addition, the summed response of the detector to a unit distance movement along the corridor is constant for a large range of grating spatial frequencies, demonstrating that the detector can be used as a visual odometer.
The STAR robot suturing intestinal tissue (credit: Azad Shademan et al./Science Translational Medicine)
Can a robot handle the slippery stuff of soft tissues that can move and change shape in complex ways as stitching goes on, normally requiring a surgeon’s skill to respond to these changes to keep suturing as tightly and evenly as possible?
A Johns Hopkins University and Children’s National Health System research team decided to find out by using their “Smart Tissue Autonomous Robot” (STAR) to perform in a procedure called anastomosis* (joining two tubular structures such as blood vessels together), using pig intestinal tissue.
The researchers published the results today in an open-access paper in the journal Science Translational Medicine. The robot surgeon took longer (up to 57 minutes vs. 8 minutes for human surgeons) but “the machine does it better,” according to Peter Kim, M.D., Professor of Surgery at the Sheikh Zayed Institute for Pediatric Surgical Innovation, Children’s National Health System in Washington D.C. Kim said the procedure was about 60 percent fully autonomous and 40 percent supervised (“we made some minor adjustments”), but that it can be made fully autonomous.
“The equivalent of a fancy sewing machine”
Automating soft tissue surgery. Left: The STAR system integrates near-infrared fluorescent (NIRF) imaging of markers (added by the surgeon to allow STAR to track surgical motions through blood and tissue occlusions), 3D plenoptic vision (captures the intensity and direction of the light rays emanating from the markers), force sensing, submillimeter positioning, and actuated surgical tools. Right: surgical site detail during linear suturing task showing a longitudinally cut porcine intestine suspended by five stay sutures. (credit: Azad Shademan et al./Science Translational Medicine)
STAR was developed by Azad Shademan and associates at the Sheikh Zayed Institute. It features a 3D imaging system and a near-infrared sensor to spot fluorescent markers along the edges of the tissue to keep the robotic suture needle on track. Unlike most other robot-assisted surgical systems, such as the Da Vinci Si, it operates without human hands-on guidance (but under the surgeon’s supervision).
In the research, the STAR robotic sutures were compared with the work of five surgeons completing the same procedure using three methods: open surgery, laparoscopic, and robot assisted surgery. Researchers compared consistency of suture spacing, pressure at which the seam leaked, mistakes that required removing the needle from the tissue or restarting the robot, and completion time.
The system promises to improve results for patients and make the best surgical techniques more widely available, according to the researchers. Putting a robot to work in this form of surgery “really levels the playing field,” said Simon Leonard, a computer scientist an assistant research professor in the Johns Hopkins Whiting School of Engineering, who worked for four years to program the robotic arm to precisely stitch together pieces of soft tissue.
As Leonard put it, they’re designing an advanced surgical tool, “the equivalent of a fancy sewing machine.”
* Anastomosis is performed more than a million times a year in the U.S.; more than 44.5 million such soft-tissue surgeries are performed in the U.S. each year. According to the researchers, complications such as leakage along the seams occur nearly 20 percent of the time in colorectal surgery and 25 to 30 percent of the time in abdominal surgery.
Carla Schaffer/AAAS | Robotic Surgery Just Got More Autonomous
Abstract of Supervised autonomous robotic soft tissue surgery
The current paradigm of robot-assisted surgeries (RASs) depends entirely on an individual surgeon’s manual capability. Autonomous robotic surgery—removing the surgeon’s hands—promises enhanced efficacy, safety, and improved access to optimized surgical techniques. Surgeries involving soft tissue have not been performed autonomously because of technological limitations, including lack of vision systems that can distinguish and track the target tissues in dynamic surgical environments and lack of intelligent algorithms that can execute complex surgical tasks. We demonstrate in vivo supervised autonomous soft tissue surgery in an open surgical setting, enabled by a plenoptic three-dimensional and near-infrared fluorescent (NIRF) imaging system and an autonomous suturing algorithm. Inspired by the best human surgical practices, a computer program generates a plan to complete complex surgical tasks on deformable soft tissue, such as suturing and intestinal anastomosis. We compared metrics of anastomosis—including the consistency of suturing informed by the average suture spacing, the pressure at which the anastomosis leaked, the number of mistakes that required removing the needle from the tissue, completion time, and lumen reduction in intestinal anastomoses—between our supervised autonomous system, manual laparoscopic surgery, and clinically used RAS approaches. Despite dynamic scene changes and tissue movement during surgery, we demonstrate that the outcome of supervised autonomous procedures is superior to surgery performed by expert surgeons and RAS techniques in ex vivo porcine tissues and in living pigs. These results demonstrate the potential for autonomous robots to improve the efficacy, consistency, functional outcome, and accessibility of surgical techniques.
TCM#2 (1995) 45×58 — Dye on paper, painted with the AARON painting machine (credit: Howard Cohen)
By Paul Cohen
Harold Cohen, artist and pioneer in the field of computer-generated art, died on April 27, 2016 at the age of 87. Cohen is the author of AARON, perhaps the longest-lived and certainly the most creative artificial intelligence program in daily use.
Cohen viewed AARON as his collaborator. At times during their decades-long relationship, AARON was quite autonomous, responsible for the composition, coloring and other aspects of a work; more recently, AARON served Cohen by making drawings that Cohen would develop into paintings. Cohen’s death is the end of a lengthy partnership between an artist and an artificial intelligence.
Cohen grew up in England. He studied painting at the Slade School of Fine Arts in London, and later taught at the Slade as well as Camberwell, Nottingham and other arts schools. He represented Great Britain at major international festivals during the 60′s, including the Venice Biennale, Documenta 3, and the Paris Biennale. He showed widely and successfully at the Robert Fraser Gallery, the Alan Stone Gallery, the Whitechapel Gallery, the Arnolfini Gallery, the Victoria and Albert Museum, and many other notable venues in England and Europe.
Then, in 1968, he left London for a one-year visiting faculty appointment in the Art Department at the University of California, San Diego. One year became many, Cohen became Department Chair, then Director of the Center for Research in Computing and the Arts at UCSD, and eventually retired emeritus in 1994.
The Last Machine Age (2015) 35.75×65.75 — Pigment ink on canvas was finger painted using Harold Cohen’s finger painting system (credit: Howard Cohen)
A scientist and engineer of art
Leaving the familiar, rewarding London scene presaged a career of restless invention. By 1971, Cohen had taught himself to program a computer and exhibited computer-generated art at the Fall Joint Computer Conference. The following year, he exhibited not only a program but also a drawing machine at the Los Angeles County Museum. A skilled engineer, Cohen built many display devices: flatbed plotters, a robotic “turtle” that roamed and drew on huge sheets of paper, even a painting robot that mixed its own colors.
These machines and the museum-goers’ experiences were always important to Cohen, whose fundamental question was, “What makes images evocative?” The distinguished computer scientist and engineer Gordon Bell notes that “Harold was really a scientist and engineer of art.”
Indeed, AARON was a thoroughly empirical project: Cohen studied how children draw, he tracked down the petroglyphs of California’s Native Americans, he interviewed viewers and he experimented with algorithms to discover the characteristics of images that make them seem to stand for something. Although AARON went through an overtly representational phase, in which images were recognizably of people or potted plants, Cohen and AARON returned to abstraction and evocation and methods for making images that produce cascades of almost-recognition and associations in the minds of viewers.
Harold Cohen and AARON: Ray Kurzweil interviews Harold Cohen about AARON (credit: Computer History Museum/Kurzweil Foundation)
“Harold Cohen is one of those rare individuals in the Arts who performs at the highest levels both in the art world and the scientific world,” said Professor Edward Feigenbaum of Stanford University’s Artificial Intelligence Laboratory, where Cohen was exposed to the ideas and techniques of artificial intelligence. “All discussions of creativity by computer invariably cite Cohen’s work,” said Feigenbaum.
Cohen had no patience for the “is it art?” question. He showed AARON’s work in the world’s galleries, museums and science centers — the Tate, the Stedelijk, the San Francisco Museum of Art, Documenta, the Boston Computer Museum, the Ontario Science Center, and many others. His audiences might have been drawn in by curiosity and the novelty of computer-generated art, but they would soon ask, “how can a machine make such marvelous pictures? How does it work?” The very questions that Cohen asked himself throughout his career.
AARON’s images and Cohen’s essays and videos can be viewed at www.aaronshome.com.
Cohen is survived by his partner Hiromi Ito; by his brother Bernard Cohen; by Paul Cohen, Jenny Foord and Zana Itoh Cohen; by Sara Nishi, Kanoko Nishi-Smith, and Uta and Oscar Nishi-Smith; by Becky Cohen; and by Allegra Cohen, Jacob and Abigail Foord, and Harley and Naomi Kuych-Cohen.
ACM SIGGRAPH Awards | Harold Cohen, Distinguished Artist Award for Lifetime Achievement
SkullConduct uses the bone conduction speaker and microphone integrated into some augmented-reality glasses and analyzes the characteristic frequency response of an audio signal sent through the user’s skull as a biometric system. (credit: Stefan Schneegass et al./Proc. ACM SIGCHI Conference on Human Factors in Computing Systems)
German researchers have developed a biometric system called SkullConduct that uses bone conduction of sound through the user’s skull for secure user identification and authentication on augmented-reality glasses, such as Google Glass, Meta 2, and HoloLens.
SkullConduct uses the microphone already built into many of these devices and adds electronics (such as a chip) to analyze the frequency response of sound after it travels through the user’s skull. The researchers, at the University of Stuttgart, Saarland University, and Max Planck Institute for Informatics, found that individual differences in skull anatomy result in highly person-specific frequency responses that can be used as a biometric system.
The recognition pipeline used to authenticate users: (1) white noise is played back using the bone conduction speaker, (2) the user’s skull influences the signal in a characteristic way, (3) MFCC features are extracted, and (4) a neuron-network algorithm is used for classification. (credit: Stefan Schneegass et al./Proc. ACM SIGCHI Conference on Human Factors in Computing Systems)
The system combines “Mel Frequency Cepstral Coefficient” (MFCC) (a feature extraction method used in automatic speech recognition) with a lightweight neural-network classifier algorithm that can directly run on the augmented-reality device.
The researchers also conducted a controlled experiment with ten participants that showed that skull-based frequency response serves as a robust biometric, even when taking off and putting on the device multiple times. The experiments showed that the system could identify users with 97.0% accuracy and authenticate them with an error rate of 6.9%.
Abstract of SkullConduct: Biometric User Identification on Eyewear Computers Using Bone Conduction Through the Skull
Secure user identification is important for the increasing number of eyewear computers but limited input capabilities pose significant usability challenges for established knowledge-based schemes, such as a passwords or PINs. We present SkullConduct, a biometric system that uses bone conduction of sound through the user’s skull as well as a microphone readily integrated into many of these devices, such as Google Glass. At the core of SkullConduct is a method to analyze the characteristic frequency response created by the user’s skull using a combination of Mel Frequency Cepstral Coefficient (MFCC) features as well as a computationally light-weight 1NN classifier. We report on a controlled experiment with 10 participants that shows that this frequency response is person-specific and stable – even when taking off and putting on the device multiple times – and thus serves as a robust biometric. We show that our method can identify users with 97.0% accuracy and authenticate them with an equal error rate of 6.9%, thereby bringing biometric user identification to eyewear computers equipped with bone conduction technology.
Deep neural networks (DNNs) are capable of learning to identify shapes, so “we’re on the right track in developing machines with a visual system and vocabulary as flexible and versatile as ours,” say KU Leuven researchers.
“For the first time, a dramatic increase in performance has been observed on object and scene categorization tasks, quickly reaching performance levels rivaling humans,” they note in an open-access paper in PLOS Computational Biology.
Categorization accuracy for models created by three DNNs (CaffeNet, VGG-19, and GoggLeNet) for three types of images (color, grayscaled, silhouette). For each type, mean human performance is indicated by a gray horizontal line, with the gray surrounding band depicting 95% confidence intervals. Error bars (vertical black lines) depict 95% confidence intervals. (credit: J. Kubilius et al./PLoS Comput Biol)
The researchers found that when trained for generic object recognition from natural photographs, several different DNNs developed visual representations that relate closely to human perceptual shape judgments, even though they were never explicitly trained for shape processing.
However, “We’re not there just yet,” say the researchers. “Even if machines will at some point be equipped with a visual system as powerful as ours, self-driving cars would still make occasional mistakes —- although, unlike human drivers, they wouldn’t be distracted because they’re tired or busy texting. However, even in those rare instances when self-driving cars would err, their decisions would be at least as reasonable as ours.”
Abstract of Deep Neural Networks as a Computational Model for Human Shape Sensitivity
Theories of object recognition agree that shape is of primordial importance, but there is no consensus about how shape might be represented, and so far attempts to implement a model of shape perception that would work with realistic stimuli have largely failed. Recent studies suggest that state-of-the-art convolutional ‘deep’ neural networks (DNNs) capture important aspects of human object perception. We hypothesized that these successes might be partially related to a human-like representation of object shape. Here we demonstrate that sensitivity for shape features, characteristic to human and primate vision, emerges in DNNs when trained for generic object recognition from natural photographs. We show that these models explain human shape judgments for several benchmark behavioral and neural stimulus sets on which earlier models mostly failed. In particular, although never explicitly trained for such stimuli, DNNs develop acute sensitivity to minute variations in shape and to non-accidental properties that have long been implicated to form the basis for object recognition. Even more strikingly, when tested with a challenging stimulus set in which shape and category membership are dissociated, the most complex model architectures capture human shape sensitivity as well as some aspects of the category structure that emerges from human judgments. As a whole, these results indicate that convolutional neural networks not only learn physically correct representations of object categories but also develop perceptually accurate representational spaces of shapes. An even more complete model of human object representations might be in sight by training deep architectures for multiple tasks, which is so characteristic in human development.

 The White House Office of Science and Technology Policy has announced plans to co-host four public workshops to spur public dialogue on artificial intelligence and machine learning, and to learn more about the benefits and risks of artificial intelligence, according to Ed Felten, a Deputy U.S. Chief Technology Officer.
The White House Office of Science and Technology Policy has announced plans to co-host four public workshops to spur public dialogue on artificial intelligence and machine learning, and to learn more about the benefits and risks of artificial intelligence, according to Ed Felten, a Deputy U.S. Chief Technology Officer.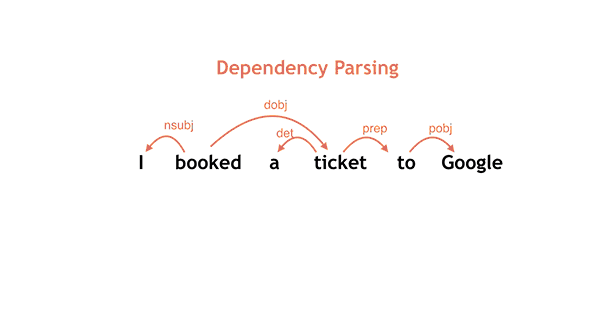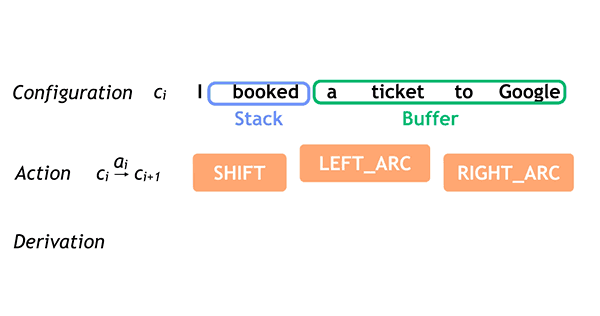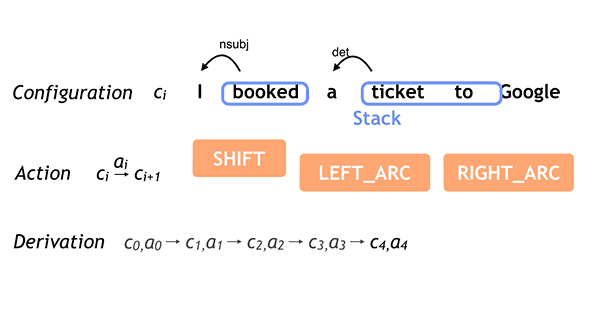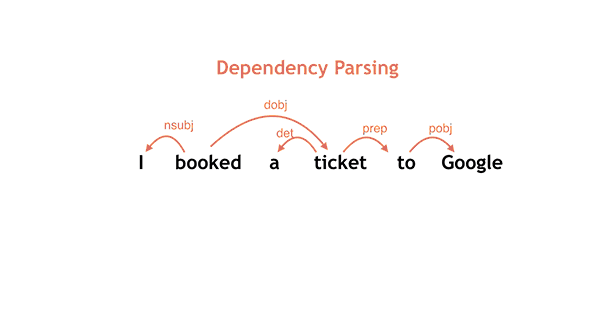 Using deep neural networks, SyntaxNet is implemented in Google’s TensorFlow (see
Using deep neural networks, SyntaxNet is implemented in Google’s TensorFlow (see 











