A sample photo (right) taken with the one-megapixel low-light Quanta Image Sensor operating at 1,040 frames per second. It is a binary single-photon image, so if the pixel was hit by one or more photons, it is white; if not, it is black. The photo was created by summing up eight frames of binary images taken continuously. A de-noising algorithm was applied to the final image. (credit: Jiaju Ma, adapted by KurzweilAI)
Engineers from Dartmouth’s Thayer School of Engineering have created a radical new imaging technology called “Quanta Image Sensor” (QIS) that may revolutionize a wide variety of imaging applications that require high quality at low light.
These include security, photography, cinematography, and medical and life sciences research.
Low-light photography (at night with only moonlight, for example) currently requires photographers to use time exposure (keeping the shutter open for seconds or minutes), making it impossible to photograph moving images.
Capturing single photons at room temperature
The new QIS technology can capture or count at the lowest possible level of light (single photons) with a resolution as high as one megapixel* (one million pixels) — scalable for higher resolution up to hundreds of megapixels per chip** — and as fast as thousands of frames*** per second (required for “bullet time” cinematography in “The Matrix”).
The QIS works at room temperature, using existing mainstream CMOS image sensor technology. Current lab-research technology may require cooling to very low temperatures, such as 4 kelvin, and is limited to low pixel count.
For astrophysicists, the QIS will allow for detecting and capturing signals from distant objects in space at higher quality. For life-science researchers, it will provide improved visualization of cells under a microscope, which is critical for determining the effectiveness of therapies.
The QIS technology is commercially accessible, inexpensive, and compatible with mass-production manufacturing, according to inventor Eric R. Fossum, professor of engineering at Dartmouth. Fossum is senior author of an open-access paper on QIS in the Dec. 20 issue of The Optical Society’s (OSA) Optica. He invented the CMOS image sensor found in nearly all smartphones and cameras in the world today.
The research was performed in cooperation with Rambus, Inc. and the Taiwan Semiconductor Manufacturing Corporation and was funded by Rambus and the Defense Advanced Research Projects Agency (DARPA). The low-light capability promises to allow for improved security uses. Fossum and associates have co-founded the startup company Gigajot Technology to further develop and apply the technology to promising applications.
* By comparison, the iPhone 8 can capture 12 megapixels (but is not usable in low light).
** The technology is based on what the researchers call “jots,” which function like miniature pixels. Each jot can collect one photon, enabling the extreme low-light capability and high resolution.
*** By comparison, the iPhone 8 can record 24 to 60 frames per second.
Abstract of Photon-number-resolving megapixel image sensor at room temperature without avalanche gain
In several emerging fields of study such as encryption in optical communications, determination of the number of photons in an optical pulse is of great importance. Typically, such photon-number-resolving sensors require operation at very low temperature (e.g., 4 K for superconducting-based detectors) and are limited to low pixel count (e.g., hundreds). In this paper, a CMOS-based photon-counting image sensor is presented with photon-number-resolving capability that operates at room temperature with resolution of 1 megapixel. Termed a quanta image sensor, the device is implemented in a commercial stacked (3D) backside-illuminated CMOS image sensor process. Without the use of avalanche multiplication, the 1.1 μm pixel-pitch device achieves 0.21e− rms0.21e− rms average read noise with average dark count rate per pixel less than 0.2e−/s0.2e−/s, and 1040 fps readout rate. This novel platform technology fits the needs of high-speed, high-resolution, and accurate photon-counting imaging for scientific, space, security, and low-light imaging as well as a broader range of other applications.
As detailed in a paper to be presented Aug. 2 at SIGGRAPH 2017, the team successfully generated a highly realistic video of former president Barack Obama talking about terrorism, fatherhood, job creation and other topics, using audio clips of those speeches and existing weekly video addresses in which he originally spoke on a different topic decades ago.
Realistic audio-to-video conversion has practical applications like improving video conferencing for meetings (streaming audio over the internet takes up far less bandwidth than video, reducing video glitches), or holding a conversation with a historical figure in virtual reality, said Ira Kemelmacher-Shlizerman, an assistant professor at the UW’s Paul G. Allen School of Computer Science & Engineering.
This beats previous audio-to-video conversion processes, which have involved filming multiple people in a studio saying the same sentences over and over to try to capture how a particular sound correlates to different mouth shapes, which is expensive, tedious and time-consuming. The new machine learning tool may also help overcome the “uncanny valley” problem, which has dogged efforts to create realistic video from audio.
How to do it
A neural network first converts the sounds from an audio file into basic mouth shapes. Then the system grafts and blends those mouth shapes onto an existing target video and adjusts the timing to create a realistic, lip-synced video of the person delivering the new speech. (credit: University of Washington)
1. Find or record a video of the person (or use video chat tools like Skype to create a new video) for the neural network to learn from. There are millions of hours of video that already exist from interviews, video chats, movies, television programs and other sources, the researchers note. (Obama was chosen because there were hours of presidential videos in the public domain.)
2. Train the neural network to watch videos of the person and translate different audio sounds into basic mouth shapes.
3. The system then uses the audio of an individual’s speech to generate realistic mouth shapes, which are then grafted onto and blended with the head of that person. Use a small time shift to enable the neural network to anticipate what the person is going to say next.
4. Currently, the neural network is designed to learn on one individual at a time, meaning that Obama’s voice — speaking words he actually uttered — is the only information used to “drive” the synthesized video. Future steps, however, include helping the algorithms generalize across situations to recognize a person’s voice and speech patterns with less data, with only an hour of video to learn from, for instance, instead of 14 hours.
Fakes of fakes
So the obvious question is: Can you use someone else’s voice on a video (assuming enough videos)? The researchers said they decided against going down the path, but they didn’t say it was impossible.
Even more pernicious: the original video person’s words (not just the voice) could be faked using Princeton/Adobe’s “VoCo” software (when available) — simply by editing a text transcript of their voice recording — or the fake voice itself could be modified.
Or Disney Research’s FaceDirector could be used to edit recorded substitute facial expressions (along with the fake voice) into the video.
However, by reversing the process — feeding video into the neural network instead of just audio — one could also potentially develop algorithms that could detect whether a video is real or manufactured, the researchers note.
The research was funded by Samsung, Google, Facebook, Intel, and the UW Animation Research Labs. You can contact the research team at audiolipsync@cs.washington.edu.
Abstract of Synthesizing Obama: Learning Lip Sync from Audio
Given audio of President Barack Obama, we synthesize a high quality video of him speaking with accurate lip sync, composited into a target video clip. Trained on many hours of his weekly address footage, a recurrent neural network learns the mapping from raw audio features to mouth shapes. Given the mouth shape at each time instant, we synthesize high quality mouth texture, and composite it with proper 3D pose matching to change what he appears to be saying in a target video to match the input audio track. Our approach produces photorealistic results.
Technology developed by Princeton University computer scientists may do for audio recordings of the human voice what word processing software did for the written word and Adobe Photoshop did for images.
“VoCo” software, still in the research stage, makes it easy to add or replace a word in an audio recording of a human voice by simply editing a text transcript of the recording. New words are automatically synthesized in the speaker’s voice — even if they don’t appear anywhere else in the recording.
The system uses a sophisticated algorithm to learn and recreate the sound of a particular voice. It could one day make editing podcasts and narration in videos much easier, or in the future, create personalized robotic voices that sound natural, according to co-developer Adam Finkelstein, a professor of computer science at Princeton. Or people who have lost their voices due to injury or disease might be able to recreate their voices through a robotic system, but one that sounds natural.
An earlier version of VoCo was announced in November 2016. A paper describing the current VoCo development will be published in the July issue of the journal Transactions on Graphics (an open-access preprint is available).
How it works (technical description)
VoCo allows people to edit audio recordings with the ease of changing words on a computer screen. The system inserts new words in the same voice as the rest of the recording. (credit: Professor Adam Finkelstein)
VoCo’s user interface looks similar to other audio editing software such as the podcast editing program Audacity, with a waveform of the audio track and cut, copy and paste tools for editing. But VoCo also augments the waveform with a text transcript of the track and allows the user to replace or insert new words that don’t already exist in the track by simply typing in the transcript. When the user types the new word, VoCo updates the audio track, automatically synthesizing the new word by stitching together snippets of audio from elsewhere in the narration.
VoCo is is based on an optimization algorithm that searches the voice recording and chooses the best possible combinations of phonemes (partial word sounds) to build new words in the user’s voice. To do this, it needs to find the individual phonemes and sequences of them that stitch together without abrupt transitions. It also needs to be fitted into the existing sentence so that the new word blends in seamlessly. Words are pronounced with different emphasis and intonation depending on where they fall in a sentence, so context is important.
Advanced VoCo editors can manually adjust pitch profile, amplitude and snippet duration. Novice users can choose from a predefined set of pitch profiles (bottom), or record their own voice as an exemplar to control pitch and timing (top). (credit: Professor Adam Finkelstein)
For clues about this context, VoCo looks to an audio track of the sentence that is automatically synthesized in artificial voice from the text transcript — one that sounds robotic to human ears. This recording is used as a point of reference in building the new word. VoCo then matches the pieces of sound from the real human voice recording to match the word in the synthesized track — a technique known as “voice conversion,” which inspired the project name, VoCo.
In case the synthesized word isn’t quite right, VoCo offers users several versions of the word to choose from. The system also provides an advanced editor to modify pitch and duration, allowing expert users to further polish the track.
To test how effective their system was a producing authentic sounding edits, the researchers asked people to listen to a set of audio tracks, some of which had been edited with VoCo and other that were completely natural. The fully automated versions were mistaken for real recordings more than 60 percent of the time.
The Princeton researchers are currently refining the VoCo algorithm to improve the system’s ability to integrate synthesized words more smoothly into audio tracks. They are also working to expand the system’s capabilities to create longer phrases or even entire sentences synthesized from a narrator’s voice.
Fake news videos?
Disney Research’s FaceDirector allows for editing recorded facial expressions and voice into a video (credit: Disney Research)
A key use for VoCo might be in intelligent personal assistants like Apple’s Siri, Google Assistant, Amazon’s Alexa, and Microsoft’s Cortana, or for using movie actors’ voices from old films in new ones, Finkelstein suggests.
But there are obvious concerns about fraud. It might even be possible to create a convincing fake video. Video clips with different facial expressions and lip movements (using Disney Research’s FaceDirector, for example) could be edited in and matched to associated fake words and other audio (such as background noise and talking), along with green screen to create fake backgrounds.
With billions of people now getting their news online and unfiltered, augmented-reality coming, and hacking way out of control, things may get even weirder. …
Zeyu Jin, a Princeton graduate student advised by Finkelstein, will present the work at the Association for Computing Machinery SIGGRAPH conference in July. The work at Princeton was funded by the Project X Fund, which provides seed funding to engineers for pursuing speculative projects. The Princeton researchers collaborated with scientists Gautham Mysore, Stephen DiVerdi, and Jingwan Lu at Adobe Research. Adobe has not announced availability of a commercial version of VoCo, or plans to integrate VoCo into Adobe Premiere Pro (or FaceDirector).
Abstract of VoCo: Text-based Insertion and Replacement in Audio Narration
Editing audio narration using conventional software typically involves many painstaking low-level manipulations. Some state of the art systems allow the editor to work in a text transcript of the narration, and perform select, cut, copy and paste operations directly in the transcript; these operations are then automatically applied to the waveform in a straightforward manner. However, an obvious gap in the text-based interface is the ability to type new words not appearing in the transcript, for example inserting a new word for emphasis or replacing a misspoken word. While high-quality voice synthesizers exist today, the challenge is to synthesize the new word in a voice that matches the rest of the narration. This paper presents a system that can synthesize a new word or short phrase such that it blends seamlessly in the context of the existing narration. Our approach is to use a text to speech synthesizer to say the word in a generic voice, and then use voice conversion to convert it into a voice that matches the narration. Offering a range of degrees of control to the editor, our interface supports fully automatic synthesis, selection among a candidate set of alternative pronunciations, fine control over edit placements and pitch profiles, and even guidance by the editors own voice. The paper presents studies showing that the output of our method is preferred over baseline methods and often indistinguishable from the original voice.
The Moogfest four-day festival in Durham, North Carolina next weekend (May 18 — 21) explores the future of technology, art, and music. Here are some of the sessions that may be especially interesting to KurzweilAI readers. Full #Moogfest2017 Program Lineup.
Culture and Technology
(credit: Google)
The Magenta by Google Brain team will bring its work to life through an interactive demo plus workshops on the creation of art and music through artificial intelligence.
Magenta is a Google Brain project to ask and answer the questions, “Can we use machine learning to create compelling art and music? If so, how? If not, why not?” It’s first a research project to advance the state-of-the art and creativity in music, video, image and text generation and secondly, Magenta is building a community of artists, coders, and machine learning researchers.
The interactive demo will go through a improvisation along with the machine learning models, much like the Al Jam Session. The workshop will cover how to use the open source library to build and train models and interact with them via MIDI.
TEDx Talks | Music and Art Generation using Machine Learning | Curtis Hawthorne | TEDxMountainViewHighSchool
Miguel Nicolelis (credit: Duke University)
Miguel A. L. Nicolelis, MD, PhD will discuss state-of-the-art research on brain-machine interfaces, which make it possible for the brains of primates to interact directly and in a bi-directional way with mechanical, computational and virtual devices. He will review a series of recent experiments using real-time computational models to investigate how ensembles of neurons encode motor information. These experiments have revealed that brain-machine interfaces can be used not only to study fundamental aspects of neural ensemble physiology, but they can also serve as an experimental paradigm aimed at testing the design of novel neuroprosthetic devices.
He will also explore research that raises the hypothesis that the properties of a robot arm, or other neurally controlled tools, can be assimilated by brain representations as if they were extensions of the subject’s own body.
Theme: Transhumanism
Dervishes at Royal Opera House with Matthew Herbert (credit: ?)
Andy Cavatorta (MIT Media Lab) will present a conversation and workshop on a range of topics including the four-century history of music and performance at the forefront of technology. Known as the inventor of Bjork’s Gravity Harp, he has collaborated on numerous projects to create instruments using new technologies that coerce expressive music out of fire, glass, gravity, tiny vortices, underwater acoustics, and more. His instruments explore technologically mediated emotion and opportunities to express the previously inexpressible.
Theme: Instrument Design
Berklee College of Music
Michael Bierylo (credit: Moogfest)
Michael Bierylo will present his Modular Synthesizer Ensemble alongside the Csound workshops from fellow Berklee Professor Richard Boulanger.
Csound is a sound and music computing system originally developed at MIT Media Lab and can most accurately be described as a compiler or a software that takes textual instructions in the form of source code and converts them into object code which is a stream of numbers representing audio. Although it has a strong tradition as a tool for composing electro-acoustic pieces, it is used by composers and musicians for any kind of music that can be made with the help of the computer and has traditionally being used in a non-interactive score driven context, but nowadays it is mostly used in in a real-time context.
Michael Bierylo serves as the Chair of the Electronic Production and Design Department, which offers students the opportunity to combine performance, composition, and orchestration with computer, synthesis, and multimedia technology in order to explore the limitless possibilities of musical expression.
Berklee College of Music | Electronic Production and Design (EPD) at Berklee College of Music
Chris Ianuzzi (credit: William Murray)
Chris Ianuzzi, a synthesist of Ciani-Musica and past collaborator with pioneers such as Vangelis and Peter Baumann, will present a daytime performance and sound exploration workshops with the B11 braininterface and NeuroSky headset–a Brainwave Sensing Headset.
Theme: Hacking Systems
Argus Project (credit: Moogfest)
The Argus Project fromGan Golan andRon Morrison of NEW INCis a wearable sculpture, video installation and counter-surveillance training, which directly intersects the public debate over police accountability. According to ancient Greek myth, Argus Panoptes was a giant with 100 eyes who served as an eternal watchman, both for – and against – the gods.
By embedding an array of camera “eyes” into a full body suit of tactical armor, the Argus exo-suit creates a “force field of accountability” around the bodies of those targeted. While some see filming the police as a confrontational or subversive act, it is in fact, a deeply democratic one. The act of bearing witness to the actions of the state – and showing them to the world – strengthens our society and institutions. The Argus Project is not so much about an individual hero, but the Citizen Body as a whole. In between one of the music acts, a presentation about the project will be part of the Protest Stage.
Argus Exo Suit Design (credit: Argus Project)
Theme: Protest
Found Sound Nation (credit: Moogfest)
Democracy’s Exquisite Corpse from Found Sound Nation and Moogfest, an immersive installation housed within a completely customized geodesic dome, is a multi-person instrument and music-based round-table discussion. Artists, activists, innovators, festival attendees and community engage in a deeply interactive exploration of sound as a living ecosystem and primal form of communication.
Within the dome, there are 9 unique stations, each with their own distinct set of analog or digital sound-making devices. Each person’s set of devices is chained to the person sitting next to them, so that everybody’s musical actions and choices affect the person next to them, and thus affect everyone else at the table. This instrument is a unique experiment in how technology and the instinctive language of sound can play a role in the shaping of a truly collective unconscious.
Theme: Protest
(credit: Land Marking)
Land Marking, fromHalsey Burgund and Joe Zibkow of MIT Open Doc Lab, is a mobile-based music/activist project that augments the physical landscape of protest events with a layer of location-based audio contributed by event participants in real-time. The project captures the audioscape and personal experiences of temporary, but extremely important, expressions of discontent and desire for change.
Land Marking will be teaming up with the Protest Stage to allow Moogfest attendees to contribute their thoughts on protests and tune into an evolving mix of commentary and field recordings from others throughout downtown Durham. Land Marking is available on select apps.
Theme: Protest
Taeyoon Choi (credit: Moogfest)
Taeyoon Choi, an artist and educator based in New York and Seoul, who will be leading a Sign Making Workshopas one of the Future Thought leaders on the Protest Stage. His art practice involves performance, electronics, drawings and storytelling that often leads to interventions in public spaces.
Taeyoon will also participate in the Handmade Computer workshop to build a1 Bit Computer, which demonstrates how binary numbers and boolean logic can be configured to create more complex components. On their own these components aren’t capable of computing anything particularly useful, but a computer is said to be Turing complete if it includes all of them, at which point it has the extraordinary ability to carry out any possible computation. He has participated in numerous workshops at festivals around the world, from Korea to Scotland, but primarily at the School for Poetic Computation (SFPC) — an artist run school co-founded by Taeyoon in NYC. Taeyoon Choi’s Handmade Computer projects.
Theme: Protest
(credit: Moogfest)
irlbb fromVivan Thi Tang, connects individuals after IRL (in real life) interactions and creates community that otherwise would have been missed. With a customized beta of the app for Moogfest 2017, irlbb presents a unique engagement opportunity.
Theme: Protest
Ryan Shaw and Michael Clamann (credit: Duke University)
Duke Professors Ryan Shaw, and Michael Clamann will lead adaily science pub talk series on topics that include future medicine, humans and anatomy, and quantum physics.
Ryan is a pioneer in mobile health—the collection and dissemination of information using mobile and wireless devices for healthcare–working with faculty at Duke’s Schools of Nursing, Medicine and Engineering to integrate mobile technologies into first-generation care delivery systems. These technologies afford researchers, clinicians, and patients a rich stream of real-time information about individuals’ biophysical and behavioral health in everyday environments.
Michael Clamann is a Senior Research Scientist in the Humans and Autonomy Lab (HAL) within the Robotics Program at Duke University, an Associate Director at UNC’s Collaborative Sciences Center for Road Safety, and the Lead Editor for Robotics and Artificial Intelligence for Duke’s SciPol science policy tracking website. In his research, he works to better understand the complex interactions between robots and people and how they influence system effectiveness and safety.
Theme: Hacking Systems
Dave Smith (credit: Moogfest)
Dave Smith, the iconic instrument innovator and Grammy-winner, will lead Moogfest’s Instruments Innovators program and host a headlining conversation with a leading artist revealed in next week’s release. He will also host a masterclass.
As the original founder of Sequential Circuits in the mid-70s and Dave designed the Prophet-5––the world’s first fully-programmable polyphonic synth and the first musical instrument with an embedded microprocessor. From the late 1980’s through the early 2000’s he has worked to develop next level synths with the likes of the Audio Engineering Society, Yamaha, Korg, Seer Systems (for Intel). Realizing the limitations of software, Dave returned to hardware and started Dave Smith Instruments (DSI), which released the Evolver hybrid analog/digital synthesizer in 2002. Since then the DSI product lineup has grown to include the Prophet-6, OB-6, Pro 2, Prophet 12, and Prophet ’08 synthesizers, as well as the Tempest drum machine, co-designed with friend and fellow electronic instrument designer Roger Linn.
Theme: Future Thought
Dave Rossum, Gerhard Behles, and Lars Larsen (credit: Moogfest)
EM-u Systems Founder Dave Rossum, Ableton CEOGerhard Behles, and LZX FounderLars Larsen will take part in conversations as part of the Instruments Innovators program.
Driven by the creative and technological vision of electronic music pioneer Dave Rossum, Rossum Electro-Music creates uniquely powerful tools for electronic music production and is the culmination of Dave’s 45 years designing industry-defining instruments and transformative technologies. Starting with his co-founding of E-mu Systems, Dave provided the technological leadership that resulted in what many consider the premier professional modular synthesizer system–E-mu Modular System–which became an instrument of choice for numerous recording studios, educational institutions, and artists as diverse as Frank Zappa, Leon Russell, and Hans Zimmer. In the following years, worked on developing Emulator keyboards and racks (i.e. Emulator II), Emax samplers, the legendary SP-12 and SP-1200 (sampling drum machines), the Proteus sound modules and the Morpheus Z-Plane Synthesizer.
Gerhard Behles co-founded Ableton in 1999 with Robert Henke and Bernd Roggendorf. Prior to this he had been part of electronic music act “Monolake” alongside Robert Henke, but his interest in how technology drives the way music is made diverted his energy towards developing music software. He was fascinated by how dub pioneers such as King Tubby ‘played’ the recording studio, and began to shape this concept into a music instrument that became Ableton Live.
LZX Industries was born in 2008 out of the Synth DIY scene when Lars Larsen of Denton, Texas and Ed Leckie of Sydney, Australia began collaborating on the development of a modular video synthesizer. At that time, analog video synthesizers were inaccessible to artists outside of a handful of studios and universities. It was their continuing mission to design creative video instruments that (1) stay within the financial means of the artists who wish to use them, (2) honor and preserve the legacy of 20th century toolmakers, and (3) expand the boundaries of possibility. Since 2015, LZX Industries has focused on the research and development of new instruments, user support, and community building.
Science
ATLAS detector (credit: Kaushik De, Brookhaven National Laboratory)
The program will include a “Virtual Visit” to the Large Hadron Collider — the world’s largest and most powerful particle accelerator — via a live video session, a ½ day workshop analyzing and understanding LHC data, and a “Science Fiction versus Science Fact” live debate.
The ATLAS experiment is designed to exploit the full discovery potential and the huge range of physics opportunities that the LHC provides. Physicists test the predictions of the Standard Model, which encapsulates our current understanding of what the building blocks of matter are and how they interact – resulting in one such discoveries as the Higgs boson. By pushing the frontiers of knowledge it seeks to answer to fundamental questions such as: What are the basic building blocks of matter? What are the fundamental forces of nature? Could there be a greater underlying symmetry to our universe?
“Atlas Boogie” (referencing Higgs Boson):
ATLAS Experiment | The ATLAS Boogie
(credit: Kate Shaw)
Kate Shaw (ATLAS @ CERN), PhD, in her keynote, titled “Exploring the Universe and Impacting Society Worldwide with the Large Hadron Collider (LHC) at CERN,” will dive into the present-day and future impacts of the LHC on society. She will also share findings from the work she has done promoting particle physics in developing countries through her Physics without Frontiers program.
The ATLAS experiment is designed to exploit the full discovery potential and the huge range of physics opportunities that the LHC provides. Physicists test the predictions of the Standard Model, which encapsulates our current understanding of what the building blocks of matter are and how they interact – resulting in one such discoveries as the Higgs boson. By pushing the frontiers of knowledge it seeks to answer to fundamental questions such as: What are the basic building blocks of matter? What are the fundamental forces of nature? Could there be a greater underlying symmetry to our universe?
Theme: Future Thought
Arecibo (credit: Joe Davis/MIT)
In his keynote, Joe Davis (MIT) will trace the history of several projects centered on ideas about extraterrestrial communications that have given rise to new scientific techniques and inspired new forms of artistic practice. He will present his “swansong” — an interstellar message that is intended explicitly for human beings rather than for aliens.
Theme: Future Thought
Immortality bus (credit: Zoltan Istvan)
Zoltan Istvan (Immortality Bus), the former U.S. Presidential candidate for the Transhumanist party and leader of the Transhumanist movement, will explore the path to immortality through science with the purpose of using science and technology to radically enhance the human being and human experience. His futurist work has reached over 100 million people–some of it due to the Immortality Bus which he recently drove across America with embedded journalists aboard. The bus is shaped and looks like a giant coffin to raise life extension awareness.
Zoltan Istvan | 1-min Hightlight Video for Zoltan Istvan Transhumanism Documentary IMMORTALITY OR BUST
Theme: Transhumanism/Biotechnology
(credit: Moogfest)
Marc Fleury and members of the Church of Space — Park Krausen, Ingmar Koch, and Christ of Veillon — return to Moogfest for a second year to present an expanded and varied program with daily explorations in modern physics with music and the occult, Illuminati performances, theatrical rituals to ERIS, and a Sunday Mass in their own dedicated “Church” venue.
NBC has teamed with AltSpaceVR to stream the U.S. presidential debate Monday night Sept. 26 live in virtual reality for HTC Vive, Oculus Rift, and Samsung Gear VR devices.
Or as late-night comic Jimmy Fallon put it, “If you’re wearing a VR headset, it will be like the candidates are lying right to your face.”
You’ll be watching the debate on a virtual screen in NBC’s “Virtual Democracy Plaza.” AltSpaceVR will also stream three other debates and Election Night on Nov. 8, as well as other VR events. You can also host your own debate watch party and make it public or friends-only.
NBC plans to host related VR events running up to the elections, including watch parties for debates, Q&A sessions with political experts, and political comedy shows.
To participate, download the AltSpace VR app for Vive, Rift, or Gear VR; also available in 2D mode for PC, Mac, Netflix, YouTube, and Twitch.
The debates will also be livestreamed on YouTube, and by Twitter (partnering with Bloomberg) and Facebook, partnering with ABC News.
Seth Rogan in poster for “The Interview” (credit: Columbia Pictures)
Seth Rogen (Freaks and Geeks, Knocked Up, Superbad) and collaborator Evan Goldberg are writing the script for a pilot for a new “half-hour comedy television series about the Singularity for FX,” Rogen revealed Thursday (August 11) on Nerdist podcast: Seth Rogen Returns (at 55:20 mark), while promoting his latest film, Sausage Party (an animated movie that apparently sets a new world record for f-bombs, based on the trailer).
“Yeah, it’s happening, I just read an article about neural dust,” said host Chris Hardwick.
“Oh, it’s happening, it’s super scary, and we’re trying to make a comedy about it,” said Rogen. “We’ll film that in the next year, basically.”
“Neural dust are, like, small particles, kind of like nano-mites, that work in your systems,” Hardwick said, “and can …” — “wipe out whole civilizations,” Rogen interjected. “But, you know, they always kinda pitch you the good stuff first: it could help your body,” Hardwick added.
(credit: Vanity Fair)
Also mentioned on the podcast: a “prank show [All People Are Famous] next week where the guy we’re pranking thinks he’s responsible for the Singularity … goes nuts, destroying everything. …”
Single-eye view of a virtual environment before (left) and after (right) a dynamic field-of-view modification that subtly restricts the size of the image during image motion to reduce motion sickness (credit: Ajoy Fernandes and Steve Feiner/Columbia Engineering)
Columbia Engineering researchers announced earlier this week that they have developed a simple way to reduce VR motion sickness that can be applied to existing consumer VR devices, such as Oculus Rift, HTC Vive, Sony PlayStation VR, Gear VR, and Google Cardboard devices.
The trick is to subtly change the field of view (FOV), or how much of an image you can see, during visually perceived motion. In an experiment conducted by Computer Science Professor Steven K. Feiner and student Ajoy Fernandes, most of the participants were not even aware of the intervention.
What causes VR sickness is the clash between the visual motion cues that users see and the physical motion cues that they receive from their inner ears’ vestibular system, which provide our sense of motion, equilibrium, and spatial orientation. When the visual and vestibular cues conflict, users can feel quite uncomfortable, even nauseated.
Decreasing the field of view can decrease these symptoms, but can also decrease the user’s sense of presence (reality) in the virtual environment, making the experience less compelling. So the researchers worked on subtly decreasing FOV in situations when a larger FOV would be likely to cause VR sickness (when the mismatch between physical and virtual motion increases) and restoring the FOV when VR sickness is less likely to occur (when the mismatch decreases).
Columbia University | Combating VR Sickness through Subtle Dynamic Field-Of-View Modification
They developed software that functions as a pair of “dynamic FOV restrictors” that can partially obscure each eye’s view with a virtual soft-edged cutout. They then determined how much the user’s field of view should be reduced, and the speed with which it should be reduced and then restored, and tested the system in an experiment.
Most of the experiment participants who used the restrictors did not notice them, and all those who did notice them said they would prefer to have them in future VR experiences.
The study was presented at IEEE 3DUI 2016 (IEEE Symposium on 3D User Interfaces) on March 20, where it won the Best Paper Award.
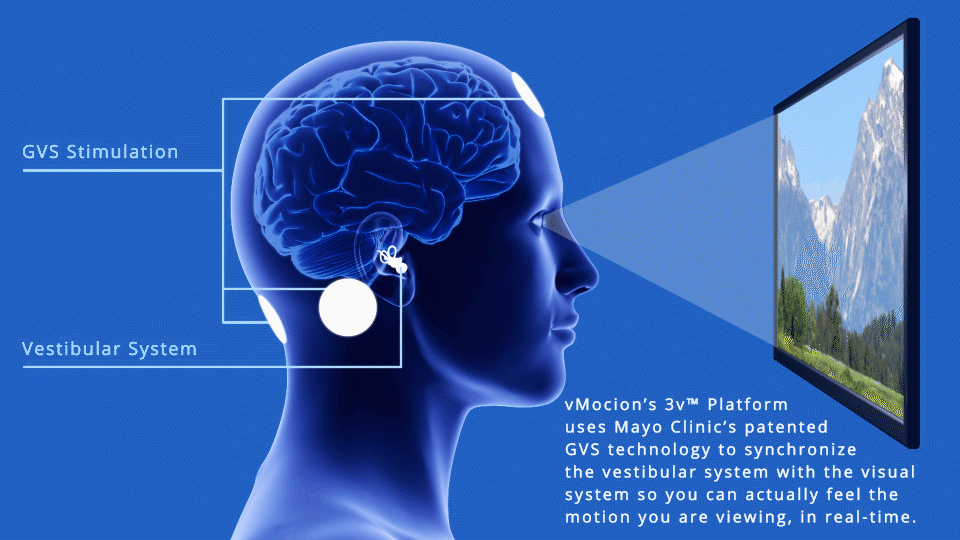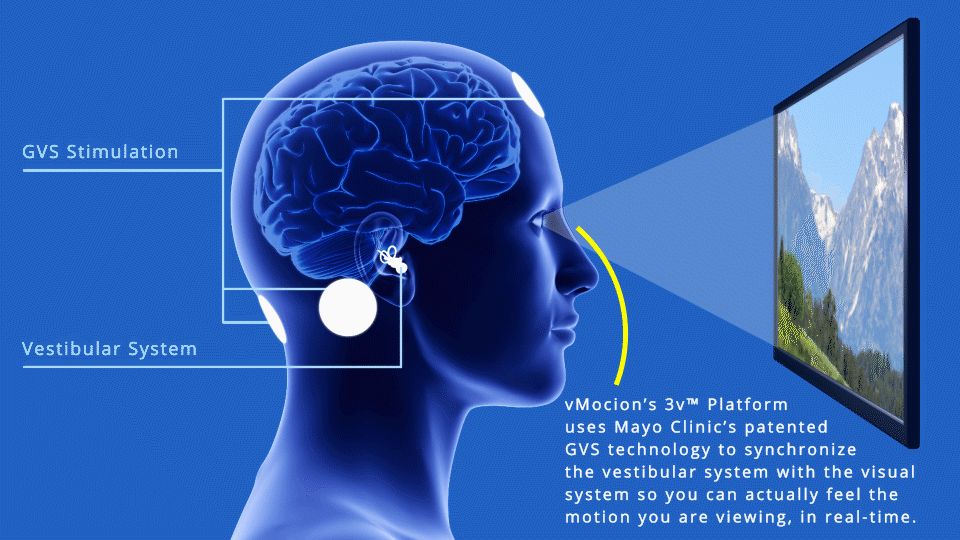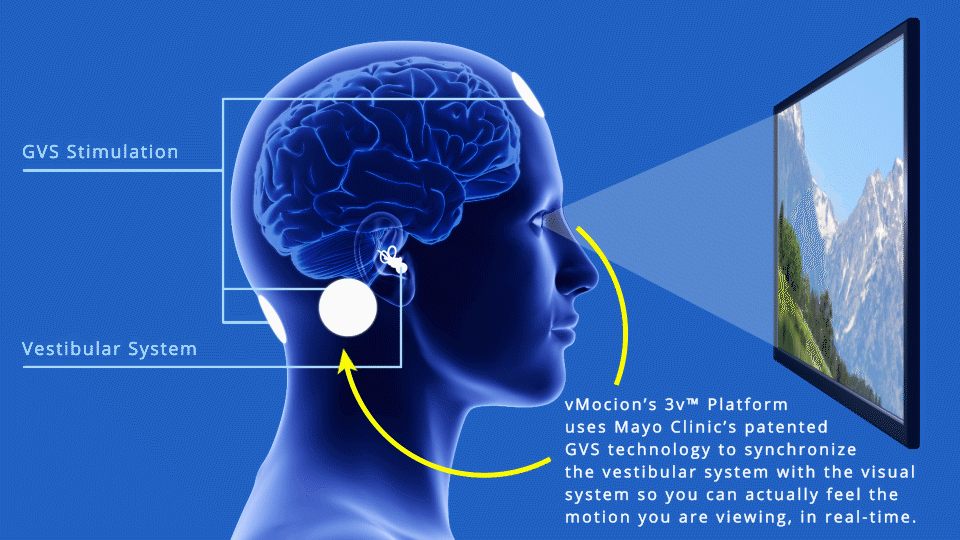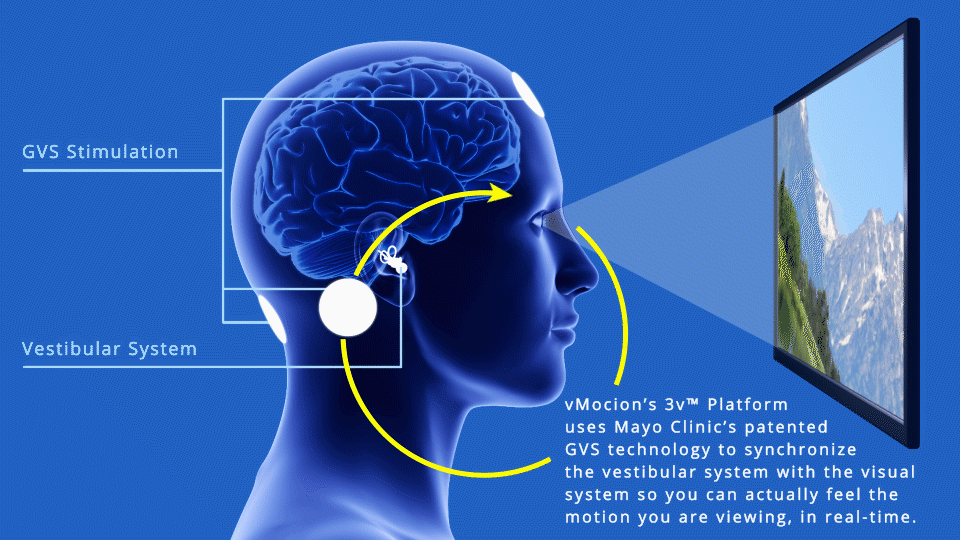
Galvanic Vestibular Stimulation
A different, more ambitious approach was announced in March by vMocion, LLC, an entertainment technology company, based on the Mayo Clinic‘s patented Galvanic Vestibular Stimulation (GVS) technology*, which electrically stimulates the vestibular system. vMocion’s new 3v Platform (virtual, vestibular and visual) was actually developed to add a “magical” sensation of motion in existing gaming, movies, amusement parks and other entertainment environments.
The 3v system can generate roll, pitch, and yaw sensations (credit: Wikipedia)
But it turns out GVS also works to reduce VR motion sickness. vMocion says it will license the 3v Platform to VR and other media and entertainment companies. The system’s software that can be integrated into existing operating systems, and added to existing devices such as head-mounted devices — along with smartphones, 3-D glasses and TVs, says Bradley Hillstrom Jr., CEO of vMocion.
vMocion | Animation of Mayo Clinic’s Galvanic Vestibular Stimulation (GVS) Technology
Integrating into VR headsets
“vMocion is are already in talks with companies in the gaming and entertainment industries,” Hillstrom told KurzweilAI, “and we hope to work with systems integrators and other strategic partners who can bring this technology directly to consumers very soon.” Hillstrom said the technology can be integrated into existing headsets and other devices.
Samsung has announced plans to sell a system using GVS, called Entrim 4D, although it’s not clear from the video (showing a Gear VR device) how it connects to the front and rear electrodes (apparently needed for pitch sensations).
Samsung | Entrim 4D
Mayo Clinic | The Story Behind Mayo Clinic’s GVS Technology & vMocion’s 3v Platform
* The technology grew out of decade-long medical research by Mayo Clinic’s Aerospace Medicine and Vestibular Research Laboratory (AMVRL) team, which consists of experts in aerospace medicine, internal medicine and computational science, as well as neurovestibular specialists, in collaboration with Vivonics, Inc., a biomedical engineering company. The technology is based on work supported by the grants from U.S. Army and U.S. Navy.
Abstract of Combating VR sickness through subtle dynamic field-of-view modification
Virtual Reality (VR) sickness can cause intense discomfort, shorten the duration of a VR experience, and create an aversion to further use of VR. High-quality tracking systems can minimize the mismatch between a user’s visual perception of the virtual environment (VE) and the response of their vestibular system, diminishing VR sickness for moving users. However, this does not help users who do not or cannot move physically the way they move virtually, because of preference or physical limitations such as a disability. It has been noted that decreasing field of view (FOV) tends to decrease VR sickness, though at the expense of sense of presence. To address this tradeoff, we explore the effect of dynamically, yet subtly, changing a physically stationary person’s FOV in response to visually perceived motion as they virtually traverse a VE. We report the results of a two-session, multi-day study with 30 participants. Each participant was seated in a stationary chair, wearing a stereoscopic head-worn display, and used control and FOV-modifying conditions in the same VE. Our data suggests that by strategically and automatically manipulating FOV during a VR session, we can reduce the degree of VR sickness perceived by participants and help them adapt to VR, without decreasing their subjective level of presence, and minimizing their awareness of the intervention.
Moogfest 2016, a four-day, mind-expanding festival on the synthesis of technology, art, and music, will happen this coming week (Thursday, May 19 to Sunday, May 22) near Duke University in Durham, North Carolina, with more than 300 musical performances, workshops, conversations, masterclasses, film screenings, live scores, sound installations, multiple interactive art experiences, and “The Future of Creativity” keynotes by visionary futurist Martine Rothblatt, PhD. and virtual reality pioneer and author Jaron Lanier.
Cyborg activist Neil Harbisson is the first person in the world with an antenna implanted in his skull, allowing him to hear the frequencies of colors (including infrared and ultraviolet) via bone conduction and receive phone calls. (credit: N. Harbisson)
By day, Moogfest unfolds in venues throughout downtown Durham in spaces that range from intimate galleries and experimental art installations to grand theaters as a platform for geeky exploration and experimentation in sessions and workshops, featuring more than 250 innovators in music, art, and technology, including avant-garde pioneers such as cyborg Neil Harbisson, technoshaman paleo-ecologist/multimedia performer Michael Garfield on “Technoshamanism: A Very Psychedelic Century,” sonifying plants with Data Garden, the Google Magenta (Deep Dream Generator) on training neural networks to generate music, Onyx Ashanti showing how to program music with your mind, Google Doodle’s Ryan Germick, and cyborg artist Moon Ribas, whose cybernetic implants in her arms perceive the movement of real-time earthquakes.
Modular Marketplace 2014 (credit: PatrickPKPR)
Among the fun experimental venues will be the musical Rube Goldberg workshop, the Global Synthesizer Project (an interactive electronic musical instrument installation where users can synthesize environmental sounds from around the world), THETA (a guided meditation virtual reality spa), WiFi Whisperer (an art installation that visually displays signals around us), the Musical Playground, and Modular Marketplace, an interactive exhibition showcasing the latest and greatest from a lineup of Moog Music and other innovative instrument makers and where the public can engage with new musical devices and their designers; free and open to the public, at the American Tobacco Campus at 318 Blackwell Street from 10am–6pm from May 19–22.
INSTRUMENT 1 from Artiphon will make its public debut at Moogfest 2016. It allows users of any skill or style to strum a guitar, tap a piano, bow a violin, or loop a drum beat — all on a single interface. By connecting to iOS devices, Macs and PCs, this portable musical tool can make any sound imaginable.
In addition, noted MIT Media Lab opera composer/inventor Tod Machover will demonstrate his Hyperinstruments, responsive stage technologies that go beyond multimedia, large-scale collaborative systems and enable entire cities to create symphonies together, and musical tools that promote wellbeing, diagnose disease, and allow for customizing compositions.
Music of the future
By night, Moogfest will present cutting-edge music in venues throughout the city. Performing artists include pioneers in electronic music like Laurie Anderson and legendary synth pioneer Suzanne Ciani, alongside pop and avant-garde experimentalists of today, including Grimes, Explosions in the Sky, Oneohtrix Point Never, Alessandro Cortini, Daniel Lanois, Tim Hecker, Arthur Russell Instrumentals, Rival Consoles, and Dawn of Midi.
Durham’s historic Armory is transformed into a dark and body-thumping dance club to host the best of electronica, house, disco and techno. Godfathers of the genre include The Orb, DJ Harvey, and Robert Hood alongside inspiring new acts such as Bicep (debuting their live show), The Black Madonna and a Ryan Hemsworth curated night including Jlin, Qrion and UVBoi.
“The liberation of LGBTQ+ people is wired into the original components of electronic music culture…” — Artists’ statement here
Local favorite Pinhook features a wide range of experimental sounds: heavy techno from Kyle Hall, Paula Temple and Karen Gwyer, live experimentation from Via App, Patricia, M. Geddes Gengras and Julia Holter, jaggedly rhythmic futurists Rabit and Lotic, and the avante-garde doom metal of The Body.
Moogfest’s largest venue, Motorco Park, is a mix of future-forward electro-pop and R&B with performances by ODESZA, Blood Orange, critically- acclaimed emerging artist DAWN (Dawn Richard) playing her first NC show, he kickoff of Miike Snow’s U.S. Tour, Gary Numan, Silver Apples, Mykki Blanco and newly announced The Range as well as a distinguished hip hop lineup that includes GZA, Skepta, Torey Lanez, Daye Jack, Denzel Curry, Lunice and local artists King Mez, Professor Toon and Well$.
Since 2004, Moogfest has brought together artists, futurist thinkers, inventors, entrepreneurs, designers, engineers, scientists, and musicians. Moogfest is a tribute to Dr. Robert “Bob” Moog and the profound influence his inventions have had on how we hear the world. Over the last sixty years, Bob Moog and Moog Music have pioneered the analog synthesizer and other technology tools for artists. He was vice president for new product research at Kurzweil Music Systems from 1984 to 1988.
Multiple recon drones in the sky all suddenly aim their cameras at a person of interest on the ground, synced to what persons on the ground see …
That could be a reality soon, thanks to an agreement just announced by the mysterious SICdrone, an unmanned aircraft system manufacturer, and CrowdOptic, an “interactive streaming platform that connects the world through smart devices.”
A CrowdOptic “cluster” — multiple people focused on the same object. (credit: CrowdOptic)
CrowdOptic’s technology lets a “cluster” (multiple people or objects) point their cameras or smartphones at the same thing (say, at a concert or sporting event), with different views, allowing for group chat or sharing content.
Drone air control
For SICdrone, the idea is to use CrowdOptic tech to automatically orchestrate the drones’ onboard cameras to track and capture multiple camera angles (and views) of a single point of interest.* Beyond that, this tech could provide vital flight-navigation systems to coordinate multiple drones without having them conflict (or crash), says CrowdOptic CEO Jon Fisher.
This disruptive innovation might become essential (and mandated by law?) as Amazon, Flirtey, and others compete to dominate drone delivery. It could also possibly help with the growing concern about drone risk to airplanes.**
Other current (and possible) users of CrowdOptics tech include first responders, news and sports reporting, advertising analytics (seeing what people focus on), linking up augmented-reality and VR headset users, and “social TV” (live attendees — using the Periscope app, for example — provide the most interesting video to people watching at home), Fisher explained to KurzweilAI.
* This uses several CrowdOptic patents (U.S. Patents 8,527,340, 9,020,832, and 9,264,474).
Familiar robot movies (credits: Disney/Pixar, Columbia Pictures, 20th Century Fox, 20th Century Fox respectively)
Older adults who recalled more robots portrayed in films had lower anxiety toward robots than seniors who remembered fewer robot portrayals, Penn State researchers found in a study.
“Increasingly, people are talking about smart homes and health care facilities and the roles robots could play to help the aging process,” said Sundar. “Robots could provide everything from simple reminders — when to take pills, for example — to fetching water and food for people with limited mobility.”
The more robot portrayals the study subjects could recall, regardless of the robot’s characteristics (even threatening ones, like the Terminator), the more they led to more positive attitudes on robots, and eventually more positive intentions to use a robot. People also had a more positive reaction to robots that looked more human-like and ones that evoked more sympathy.
The most recalled robots included robots from Bicentennial Man, Forbidden Planet, Lost In Space, Star Wars, The Terminator, Transformers, Wall-E, and I, Robot.
Abstract of The Hollywood Robot Syndrome: Media Effects on Older Adults’ Attitudes toward Robots and Adoption Intentions
Do portrayals of robots in popular films influence older adults’ robot anxiety and adoption intentions? Informed by cultivation theory, disposition theory and the technology acceptance model, the current survey (N = 379) examined how past exposure to robots in the media affect older adults’ (Mage = 66) anxiety towards robots and their subsequent perceptions of robot usefulness, ease of use, and adoption intentions. The results of a structural equation model (SEM) analysis indicate that the higher the number of media portrayals recalled, the lower the anxiety towards robots. Furthermore, recalling robots with a human-like appearance or robots that elicit greater feelings of sympathy was related to more positive attitudes towards robots. Theoretical and practical implications of these results for the design of socially assistive robots for older adults are discussed.